Model Evaluation

Carlos Salas
Portfolio Manager and Data Scientist
Evaluating model performance for accuracy is crucial. But models are a simplified version of reality and are prone to model error. Join Carlos Salas in this video as he explores the 3 kinds of model error and how to find the right balance.

Evaluating model performance for accuracy is crucial. But models are a simplified version of reality and are prone to model error. Join Carlos Salas in this video as he explores the 3 kinds of model error and how to find the right balance.
Model Evaluation
7 mins 46 secs
Key learning objectives:
Identify the 3 types of model error
Understand how to fix model errors
Overview:
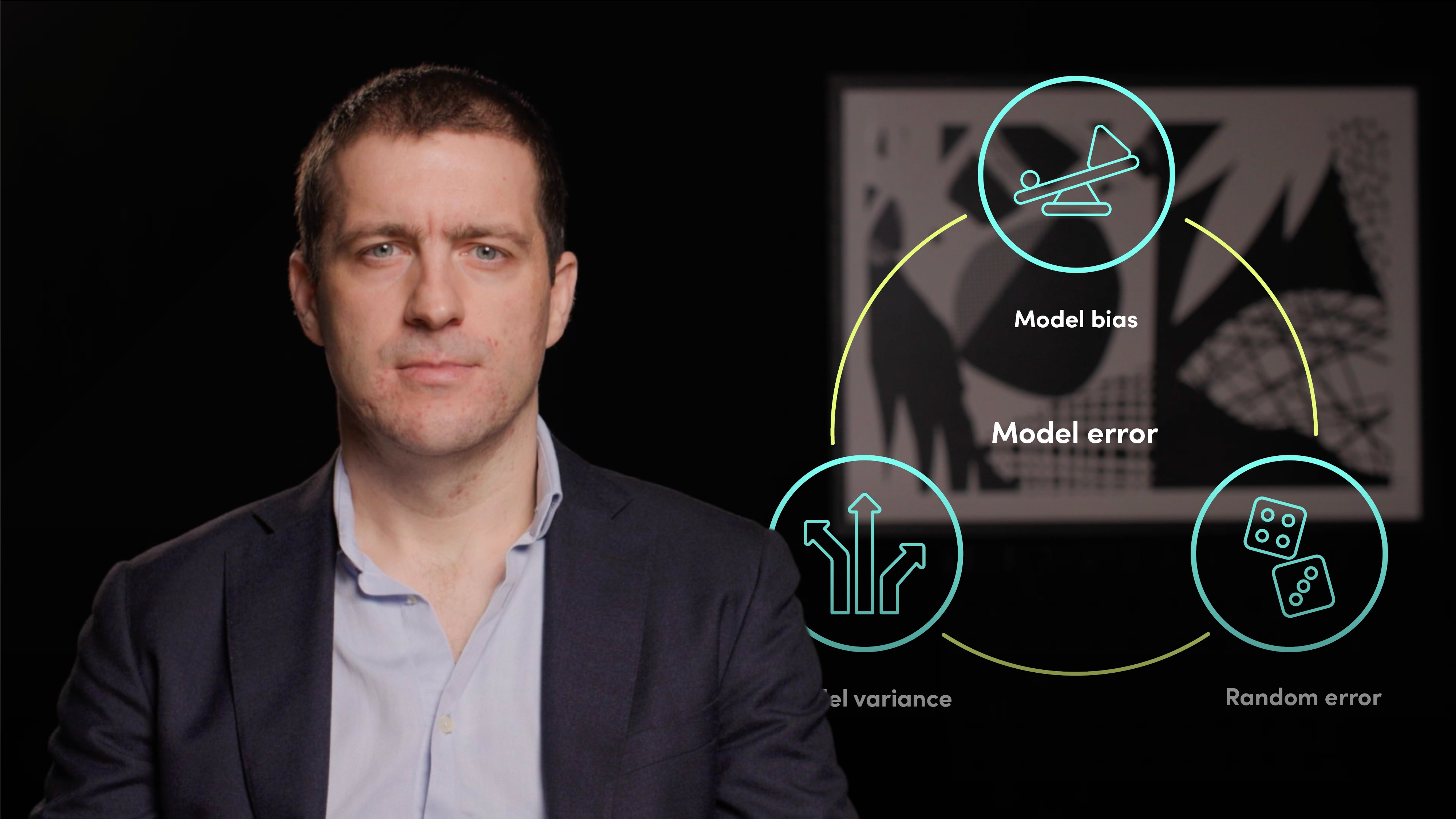
Measuring a model’s performance is one of the most important aspects of the data science workflow. There are 3 types of model error to be aware of: model bias (originating from erroneous assumptions in the learning algorithm), model variance (how sensitive the model is to small fluctuations in the utilised training dataset) and random error. The right path for a data scientist is to always try to find a model that has a balance between accuracy and precision, called the bias-variance trade-off. Fixing high bias can be achieved by adding more input features or by increasing the complexity of the model. Fixing high variance models can be achieved by using more training data and reducing the number of features so that only the most important are considered.
What are the 3 types of model error?
1. Model bias. An error originating from erroneous assumptions in the learning algorithm. Models suffering from high bias can cause an algorithm to miss the relevant relations between features and the response variable, commonly referred to as underfitting.
2. Model variance. This is related to the instability of the model - how sensitive the model is to small fluctuations in the utilised training dataset. Models suffering from high variance can cause an algorithm to miss relevant relations, commonly referred to as overfitting.
3. Random error. A model is a simplification of reality and can never be perfect, so it will therefore always suffer from random errors. A different way of interpreting the random error is by looking at it as a measure of the amount of data noise present.
How can you fix model error?
As random error is inevitable, the only two error components that can be minimised are bias and variance. The right path for a data scientist is to always try to find a model that has a balance between accuracy and precision, called the bias-variance trade-off.
Fixing high bias can be achieved by adding more input features or by increasing the complexity of the model. Fixing high variance models can be achieved by using more training data and reducing the number of features so that only the most important are considered.

Carlos Salas
There are no available Videos from "Carlos Salas"